
国立国語研究所 〒190-8561 東京都立川市緑町10-2 Tel. 0570-08-8595 (ナビダイヤル)
© National Institute for Japanese Language and Linguistics
2018年12月に、世界で初となる映像付きの日常会話コーパス(50時間分)を公開しました。利用を希望される方は【こちらの申請ページ】をご覧ください。
『日本語日常会話コーパス』(Corpus of Everyday Japanese Conversation, CEJC)は、 さまざまな場面における自然な日常会話をバランスよく収めたコーパスです。 研究の可能性を広げるために、映像まで含めて公開しています。 映像付きの大規模日常会話コーパスは世界初の試みです。

さまざまな場面における会話を収集するために、 性別・年齢などの観点からバランスを考慮して選別された 40名の調査協力者の方々に機材機器を3か月ほど貸し出し、 協力者の日常生活で自然に生じる会話を協力者自身に記録してもらいました。
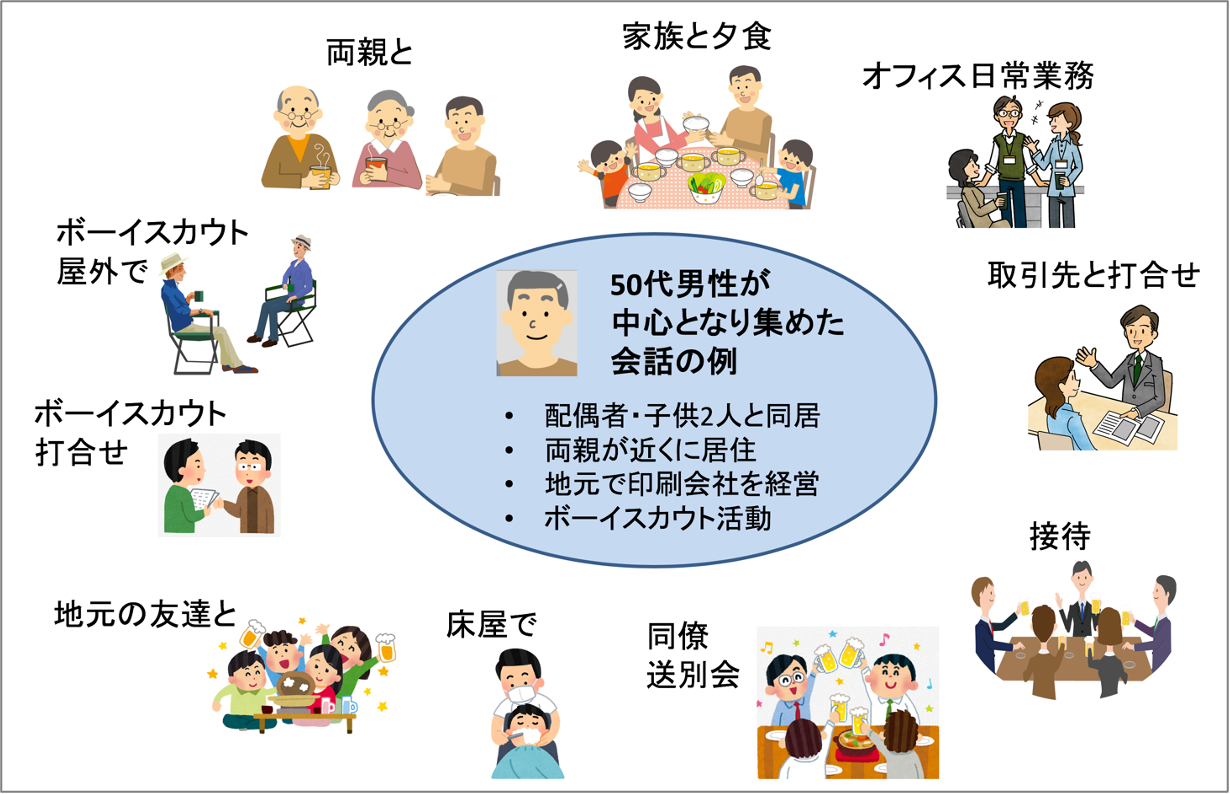
例えば30代の専業主婦の方には、 ご家族との朝食場面・子供の宿題を見る場面・旅行等レジャー場面の会話や、 夫の実家に帰省した際の会話、 子供のPTA関連の打合せ場面の会話、 ママ友とのランチ会の会話など、 さまざまな場面、さまざまな相手との会話を集めていただきました。
収録した200時間の会話は、文字化した上で、 形態論情報や係り受け情報などのアノテーションを行い、 検索可能な形に整備して、2021年度末に一般公開します。 またそれに先立ち、2018年12月に50時間分のデータを公開しました。 言語学や日本語教育、心理学、認知科学、情報工学など、 多様な分野の研究者が研究に活用するだけでなく、 AIなど通信技術を中心とする産業界からも注目されています。
2021年度に予定している本公開に先立ち、 コーパスの利用可能性や問題などを把握するために、 2018年12月に50時間分のデータをモニター公開しました。 次の二つの方式で公開しています。
オンライン検索システム『中納言』での公開
ハードディスクでの公開
モニター公開版の詳細については以下をご覧ください。
| データの仕様・関連文献 | 関連データ・ツール | 利用ガイドライン |
|---|---|---|
| データ概要 | 調査協力者一覧 | 利用者の範囲・利用期限 |
| 会話・話者のメタ情報 | 会話一覧 | 成果の公表に際して |
| 転記テキスト | 語彙表 | 利用目的の範囲・利用方法 |
| 短単位情報 | その他のデータ | 授業や演習等での利用について |
| 映像・音声データ | ツール | バグ報告 |
| 関連文献 | FAQ |
日常の言語生活を反映したコーパスを作成するには、私たちが普段、どのような会話をどの程度行っているのか、その実態を知る必要があります。 そこで、約250名を対象に、起床から就寝までの間に行った全ての会話について、いつ、どこで、誰と、何をしながら、どのような種類の会話を、どのくらいの長さ行ったか、などを問う調査をしました。
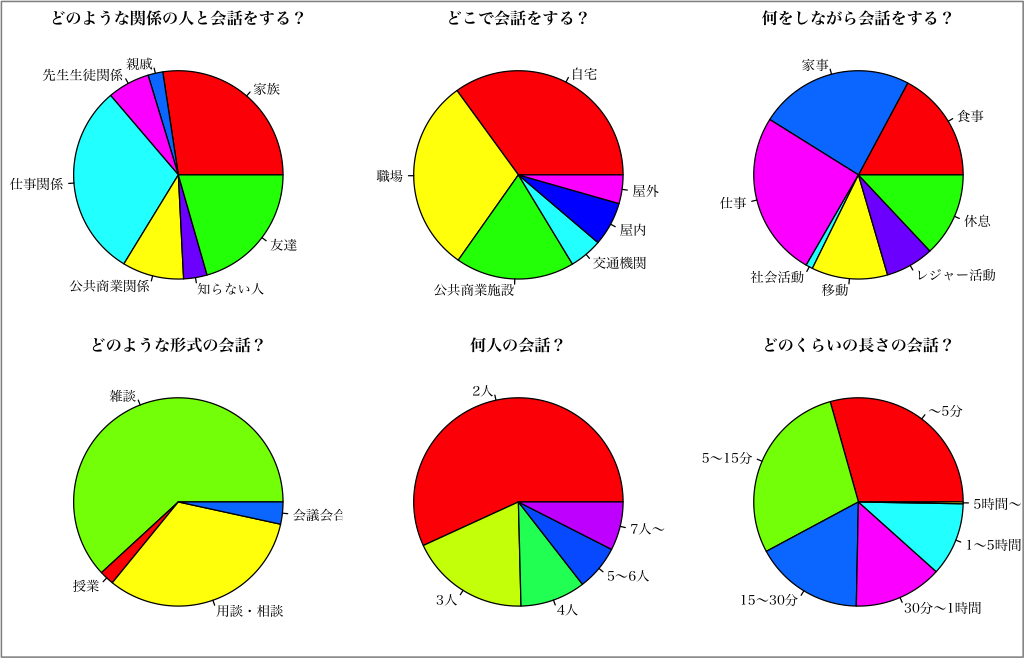
この結果を参考に、多様な場面の日常会話を収録します。調査の詳細や生データのダウンロードは【こちら】をご覧ください。