
国立国語研究所 〒190-8561 東京都立川市緑町10-2 Tel. 0570-08-8595 (ナビダイヤル)
© National Institute for Japanese Language and Linguistics
『日本語日常会話コーパス』(Corpus of Everyday Japanese Conversation, CEJC)の特徴は、 以下の3点です。
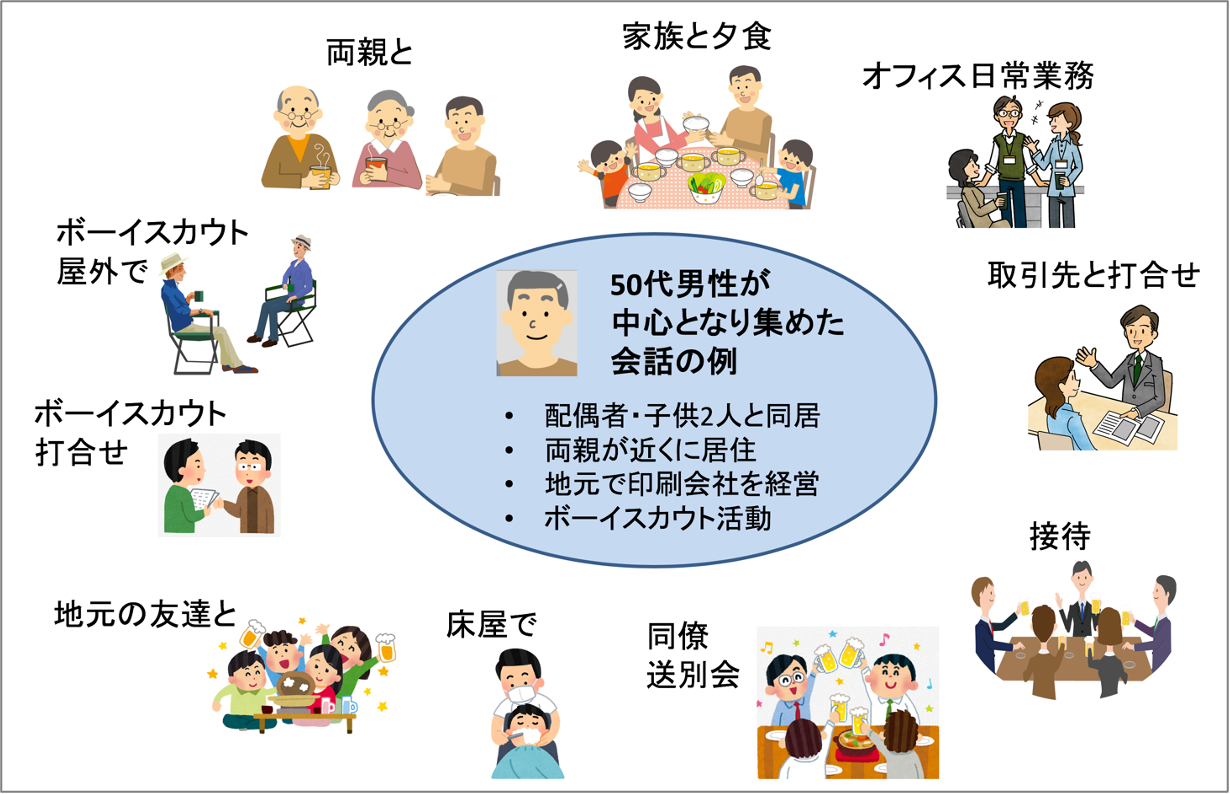
■ 個人密着法
性別・年齢などの観点からバランスを考慮して選別された協力者40名(20代・30代・40代・50代・60歳以上の男女、各4名)に機材機器等を2-3か月ほど貸し出し、
協力者の日常生活で自然に生じる会話を協力者自身に記録してもらいました。
できるだけ多様な場面・多様な話者との会話を対象にするようお願いしました。
プロジェクトのメンバーは収録に立ち合いません。
コーパス200時間のうち185時間をこの方法で収録しました。収録時期は2016〜2019年です。
■ 特定場面法
個人密着法で収録された会話のバランスを検証し、不足する会話の種別を特定した上で、その不足を補うために、 仕事中の会議会合を約10時間、中高生の雑談・打合せ等を約5時間、 計15時間を追加で収集しました。収録時期は2019〜2020年です。
多様な会話をバランスよく集めるために、 予備調査として会話行動の実態調査を行いました。 この結果を一つの目安として、コーパスに格納するデータの選定を進めています。 モニター公開対象についても、構築状況を見ながらできるだけ多様な会話が含まれるように選定しました。
採用した収録方法では、収録を始める前に、 協力者自身が、機材の設定や他の話者への主旨説明などをする必要があるため、 話題が進んだところから収録が開始されることもあります。 また1回の収録は最大でも1時間程度としており、会話の途中で収録が切れることもあります。 そのため、協力者が1回に収録したもの(これをセッションと呼びます)から、 ある程度のまとまりをもった範囲を「会話」として切り出し、 コーパスに格納するデータを決めています。 倫理的・法的な問題や会話者の希望などを考慮し、問題のある部分をカットした結果、 一つの収録データが複数の会話に分かれることもあります。
用語
200時間に対して、映像データ、音声データ、転記テキスト、短単位情報(人手修正)、長単位情報(自動解析)を提供します。また、個人密着法で収録した会話185時間の中から20時間を選別して「コア」とし、人手修正・付与した複数のアノテーションを提供します。
| コーパス全体 | コア | 「中納言」版の対象 | 仕様 | |
|---|---|---|---|---|
| 映像データ | ○ | ○ | × | ☞ こちら |
| 音声データ | ○ | ○ | 検索箇所前後の再生 | ☞ こちら |
| 転記テキスト | ○ | ○ | × | ☞ こちら |
| 形態論情報(短単位情報) | ○ | ○ | ○ | ☞ こちら |
| 形態論情報(長単位情報) | ○ | ○ | ○ | ☞ こちら |
| 談話行為情報 | × | ○ | × | ☞ こちら |
| 韻律情報 | × | ○ | × | ☞ こちら |
| 会話・話者に関するメタ情報 | ○ | ○ | △(備考等除く) | ☞ こちら |
また、データの規模は次の通りです。
| コーパス全体 | うち「コア」 | |
|---|---|---|
| 時間数 | 200時間 | 20時間 |
| セッション数 | 461セッション | 52セッション |
| 会話数 | 577会話 | 52会話 |
| 延べ話者数 | 1675名 | 169名 |
| 異なり話者数 | 862名 | 135名 |
| 語数(短単位) | 約240万語 | 約25万語 |
| 発話単位数 | 577,885 | 59,324 |
『日本語日常会話コーパス』は、 実際の日常場面の会話を、映像・音声データまで含めて公開しますが、 その中には、公開の承諾を得ていない第三者の顔や テレビなどの著作物の写り込みなどが多く見られます。 そこで本プロジェクトでは、 これまでに収録した多様な会話データをもとに具体的な問題を洗い出し、 肖像権や個人情報保護、著作権などの観点からデータの公開方針を定めました。 本コーパスはこの方針に従ってデータを整備しています。 データの公開方針の詳細は以下の文献をご覧ください。